
V rámci zvyšovania kvalifikácie a otestovania vlastných schopností a vedomostí sa náš kolega, dátový analytik, Martin Demeter zúčastnil celosvetovej súťaže v oblasti dátovo-centrovanej umelej inteligencie (DCAI). Súťaže sa celkovo zúčastnilo 677 účastníkov. Martin si odniesol cenu v kategórii najinovatívnejšie riešenie a podarilo sa mu získať v silnej konkurencii aj výborné 2. miesto.
Súťaž Data-Centric AI Competition 2023 organizovali Cleanlab a MachineHack. Trvala osem týždňov a skladala sa z dvoch častí zameraných na analýzu textových a obrazových dát. Úlohou bolo použiť klasifikátory strojového učenia, naučené na trénovacích datasetoch, na predikciu správnej triedy dát z testovacieho súboru. Poskytnuté trénovacie dáta však obsahovali chyby v anotáciách. Súťažiaci sa teda mali zamerať na data (data-centric AI), nie na modely (model-centric AI) pri riešení problému.

Hlavným cieľom tejto súťaže bolo predpovedať správnu triedu spojenú s každým dátovým bodom v testovacej sade pomocou klasifikátora strojového učenia, ktorý bol naučený na trénovacej sade dát. Trénovacie dáta v týchto súťažiach obsahujú reálne chyby a odchýlky. Účastníci sú preto vyzývaní na prístup zameraný na dáta pri riešení problému a na využitie nástrojov, ako je napríklad cleanlab a mnohé iné dostupné open-source nástroje.
Súťaž č. 1 bola zameraná na textové dáta. Išlo o predikciu hodnotenia (rating) z recenzií Amazonu s pridruženým hodnotením v podobe hviezdičiek (klasifikácia textu). Pri tomto zadaní Martin použil transformátory, detekciu outlierov, analýzu sentimentu a vizualizáciu.
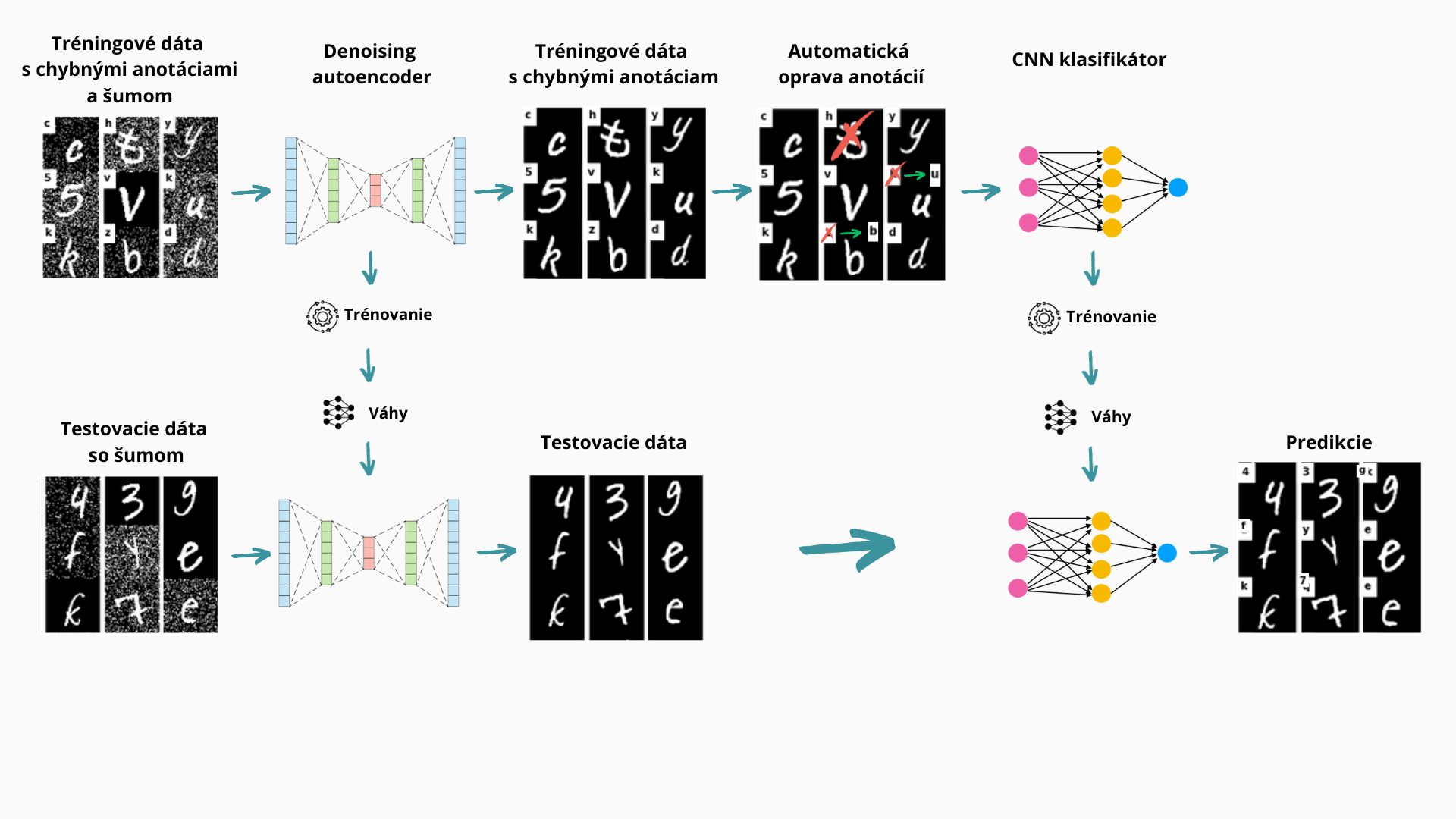
Súťaž č. 2 sa zaoberala obrazovými dátami, ktoré obsahujú alfa-numerické znaky. Išlo o predikciu znakov z obrazu (podobné ako dataset MNIST). Účastníci majú vytvoriť a optimalizovať klasifikačný model, ktorý predpovedá typ znaku na základe daného obrázku. Pri riešení tejto úlohy Martin použil denoising autoenkóder a klasifikátor na báze CNN.
Cleanlab, ktorý vznikol v rámci doktorandského výskumu na MIT (Massachusetts Institute of Technology), je nástroj používaný poprednými organizáciami na zlepšenie výkonu modelov strojového učenia identifikáciou a riešením problémov s dátami a označeniami v reálnych datasetoch. Cleanlab vyvíja open-source balíček cleanlab, ktorý je najpoužívanejší balíček DCAI na platforme GitHub, kde verejne uvoľňujú algoritmy DCAI nasledujúcej generácie bezplatne.
Prečo si sa rozhodol zapojiť do tejto súťaže?
Hlavným dôvodom bolo vyskúšať techniky a nástroje, ktoré vyvinul organizátor súťaže Cleanlab. Cleanlab vytvoril framework (cleanlab studio) a sadu pythonových knižníc, ktoré sa zameriavajú na riešenie chýb, ktoré nastavajú pri anotácii tréningových údajoch človekom. Chyby v anotácii môžu výrazne ovplyvniť výkon a spoľahlivosť modelov strojového učenia. Príprava údajov a zvlášť anotácia údajov je časovo najnáročnejšia a najnudnejšia časť vývoja AI riešení a každý nástroj, ktorý môže tento proces uľahčiť, je atraktívny.
Ako si zvládol výzvy súťaže? Čo boli najväčšie prekážky, s ktorými si sa stretol počas súťaže, a ako si ich prekonal?
Súťaž bola rozdelená na dve úlohy. V prvej úlohe bolo potrebné natrénovať klasifikátor, ktorý na základe textovej recenzie online produktov dokáže predpovedať hodnotenie (hviezdičky). V tejto časti úlohy som si musel naštudovať a použiť najnovšie postupy v oblasti NLP (natural language processing) – transformery (modely, na ktorých je založený aj ChatGPT), analýza sentimentu, redukcia dimenzionality. Druhá časť súťaže bola zameraná na spracovanie obrazu. Bolo potrebné natrénovať klasifikátor, ktorý rozpozná správne znaky z obrazu. Musel som sa oboznámiť s technológiami CNN (konvolučných neurónových sietí) a denoising autoencodérov. V oboch úlohách bol však poskytnutý tréningový dataset, ktorý obsahoval veľké množstvo anotačných chýb, čo si vyžadovalo použitie techník outlier detekcií, s ktorými som nemal hlboké skúsenosti.
Koľko času a úsilia si tomu celkovo venoval?
Počas súťaže bolo možné presnosť modelov testovať na validačnej vzorke, pričom každý účastník videl presnosť modelov ostatných súťažiacich. Od začiatku súťaže som videl, že sa nachádzam v oboch úlohách na prvých miestach. To ma tlačilo k tomu, aby som svoje riešenia ešte zlepšoval, takže som na tom strávil pomerne veľa času. Dokopy to mohlo byť aj 40 hodín práce.
Má tvoje víťazstvo vplyv na tvoju ďalšiu prácu v oblasti DCAI? Máš nejaké plány súvisiace s touto oblasťou do budúcnosti?
Súťaž mi prehĺbila moje presvedčenie o dôležitosti data-centric prístupu pri tvorbe AI riešení. Tento prístup hovorí o tom, že dôležitejšie je pri vývoji sústrediť sa na kvalitné dáta ako na vývoj nových architektúr modelov (model-centric AI). Dnes už máme k dispozícii dostatočne silné modely, ktoré dosahujú v niektorých úlohách lepšie výsledky ako človek. Modely sa tiež stali veľmi ľahko dostupnými. Platformy ako HuggingFace umožňujú implementovať tieto modely na 5 riadkov kódu. Najväčší problém je v dostupnosti kvalitných dát, na ktorých tieto modely môžeme trénovať. Preto sa v budúcnosti budem ešte viac venovať témam zameraným na data management, data quality, data monitoring a technikám MLOps, ktoré umožňujú automatizované pretrénovanie modelov vždy, keď nastane zmena v dátach (napr. data drift).

Čo považuješ za najväčšie výhody a prínosy súťaží tohto typu?
Myslím, že je to veľmi zaujímavý formát, ako môžu nové firmy, ako je CleanLab, upútať pozornosť na svoje produkty. Pre mňa osobne bolo zaujímavé si ich technológie vyskúšať, niečo nové sa naučiť, ešte si aj zasúťažiť a vyhrať finančnú odmenu.

Naše riešenia_
Mohlo by sa vám páčiť

Čítať viac

Čítať viac

Čítať viac